What is Apache Fluss?
One platform. Streams, tables, and the lakehouse. Apache Fluss is an open-source streaming storage system for real-time analytics and AI, designed to serve as the real-time data layer of a Lakehouse architecture.
Fluss collapses the message broker, the online key-value store, the stream-processing state backend, and the lakehouse cold store into a single coherent foundation, so the same table can be read at sub-second freshness for analytics, looked up by primary key for features, and tiered into open formats like Apache Iceberg, Apache Paimon, or Lance for historical scans.
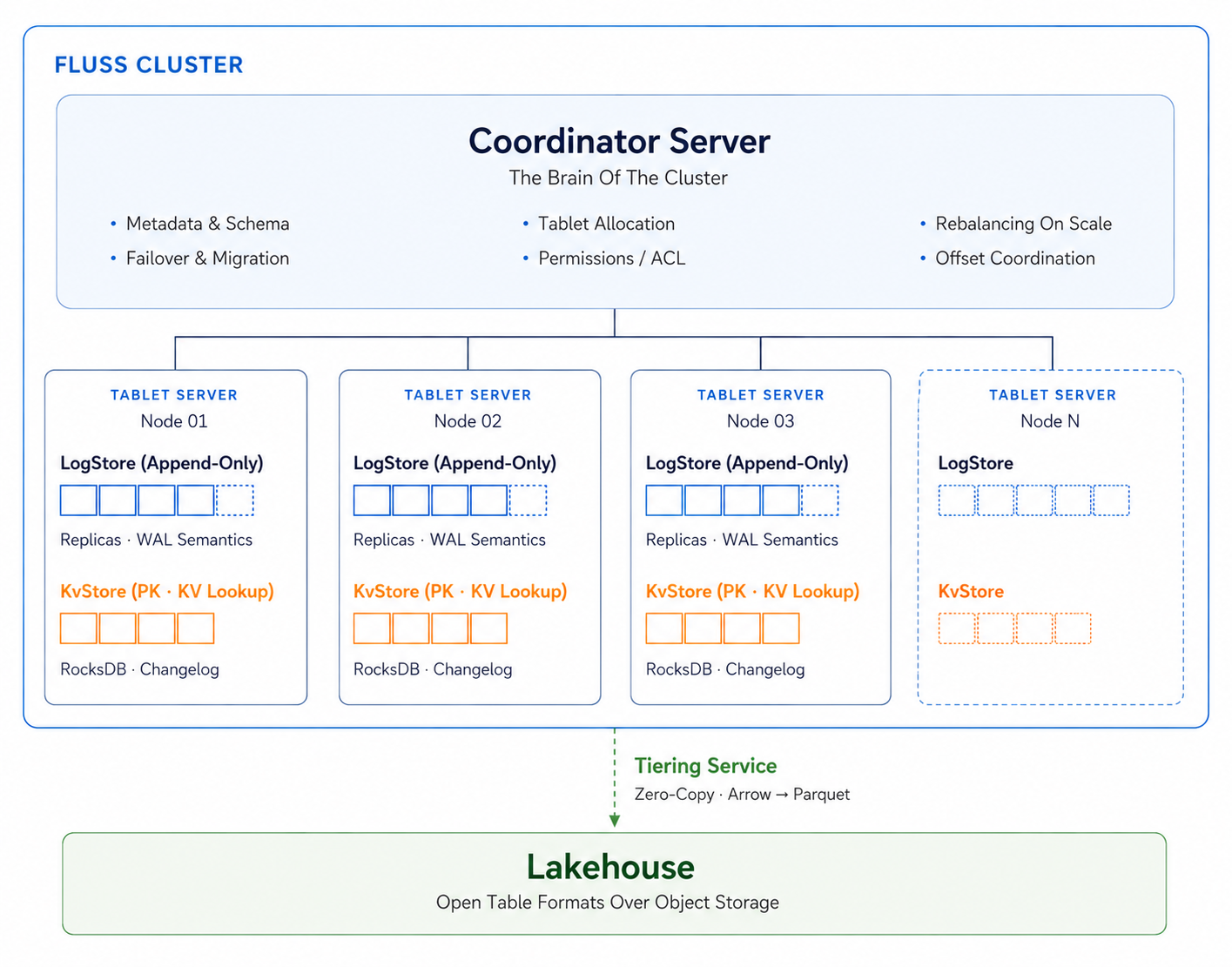
It integrates first-class with Apache Flink and Apache Spark, supports streaming reads and writes with sub-second latency, stores data in a columnar layout for projection and predicate pushdown, and offers two table types (append-only Log Tables and updatable PrimaryKey Tables) to cover both event-stream and database-style workloads.
Fluss (German: river, pronounced /flus/) carries streaming data continuously into lakes, like a river 🌊
Use cases
Fluss targets workloads where the same data must be read at multiple freshness layers (stream, point-lookup, and lake) without being copied across systems. Six use cases drive most deployments today.
1. Real-time feature stores for ML serving and training
The single largest use case. A Fluss PrimaryKey Table holds the live feature row in RocksDB on the leader for sub-millisecond key-value lookup at serving time, and the ordered changelog for training reads. Both views read the same underlying storage, so training/serving skew is structurally eliminated rather than monitored after the fact. Replaces the typical Redis-online-store plus Iceberg-offline-store pair with a single substrate.
2. Real-time risk, fraud detection, and decision audit
PrimaryKey Tables emit a complete +I / -U / +U / -D changelog for every entity. When a real-time decision fires (decline a transaction, flag an account, deny a request), the exact feature values that drove it trace directly back to a specific changelog record, so the decision is fully reconstructible from the log itself, with no secondary audit pipeline.
3. Real-time entity profiles and Customer 360
The Aggregation Merge Engine combined with Roaring Bitmaps lets the leader maintain large entity sets such as "users who clicked in the last ten minutes" or "accounts that crossed a usage threshold today", via at-write-time read-modify-write. Profile composition reduces to set algebra (AND / OR / AND NOT) over bitmap columns. Multiple producers can write disjoint columns of the same wide row independently via partial updates.
4. AI agent memory and context engineering for LLM systems
Four distinct memory primitives live in the same substrate under a consistent schema surface:
- Session memory: conversation logs
- Entity memory: live key-value facts
- Behavioral memory: streaming features
- Semantic memory: vector store via Lance
An agent reads all four concurrently to assemble a grounded prompt, with no cross-system synchronization.
5. Real-time operational analytics and OLAP hot-store replacement��
The columnar Arrow log plus server-side compound pruning (partition pruning, predicate pushdown, column projection) lets analytical engines such as Flink batch, Spark, Trino, StarRocks, and DuckDB query the hot tier directly. The result is order-of-magnitude reductions in I/O, network, and deserialization cost. Replaces the typical "OLAP hot store" sitting alongside Kafka.
6. Streaming ETL with externalized state
Stateful streaming ETL pipelines (joins, rolling aggregations, deduplication, reference-data enrichment, wide-row assembly across multiple producers) traditionally accumulate gigabytes of operator state inside Flink that must be checkpointed, recovered, and rebalanced on scale-out. With Fluss, that state moves into PrimaryKey Tables on the leader and the Flink job becomes stateless: dual-stream joins collapse into stateless index-key lookups via delta joins, rolling counts and velocity signals collapse into writes against the Aggregation Merge Engine, and multi-producer wide-row updates collapse into partial-updates against a shared row.
Where to go next?
- QuickStart: Get started with Fluss in minutes.
- Architecture: Learn about Fluss's architecture.
- Table Design: Explore Fluss's table types, partitions and buckets.
- Lakehouse: Integrate Fluss with your Lakehouse to bring low-latency data to your Lakehouse analytics.
- Development: Set up your development environment and contribute to the community.