Tiering Service Deep Dive

Background
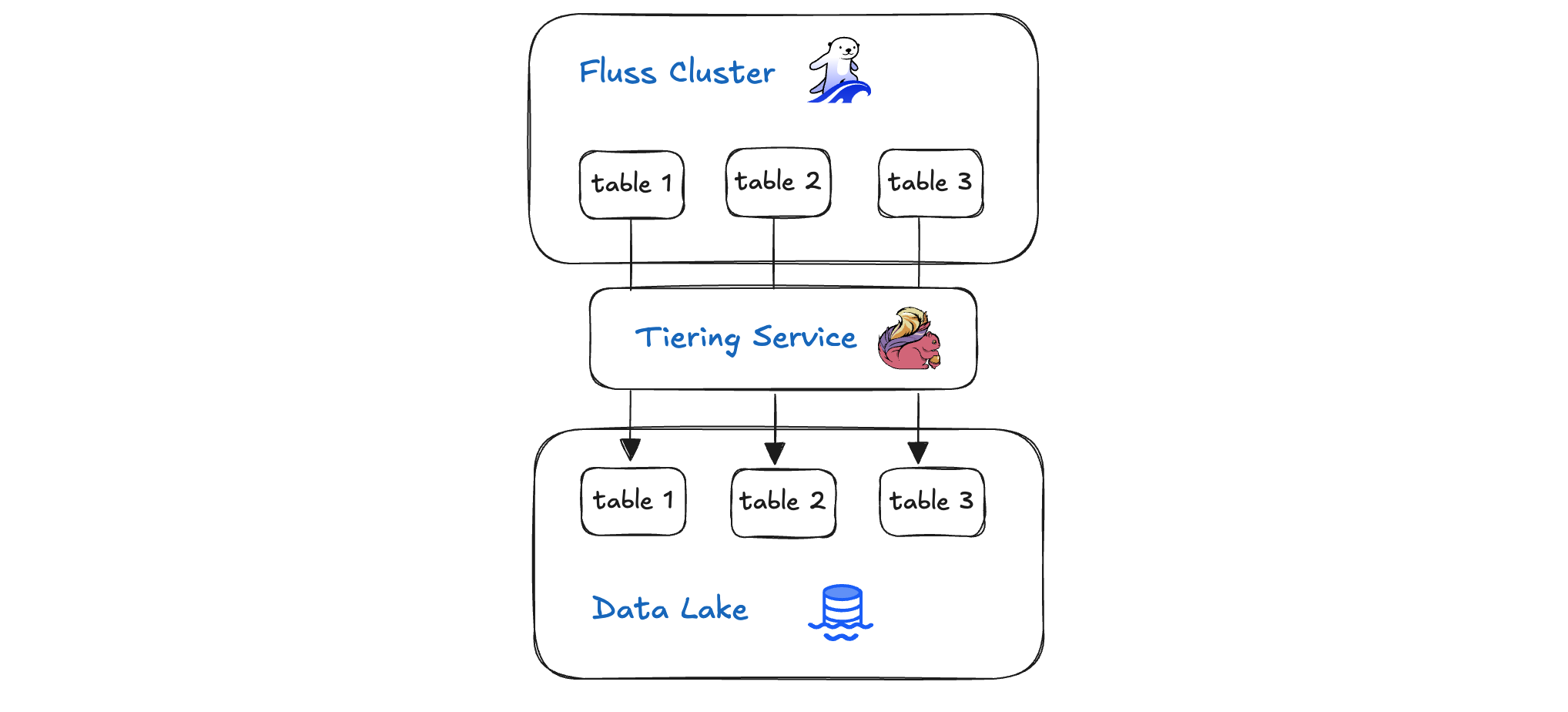
At the core of Fluss’s Lakehouse architecture sits the Tiering Service: a smart, policy-driven data pipeline that seamlessly bridges your real-time Fluss cluster and your cost-efficient lakehouse storage. It continuously ingests fresh events from the fluss cluster, automatically migrating older or less-frequently accessed data into colder storage tiers without interrupting ongoing queries. By balancing hot, warm, and cold storage according to configurable rules, the Tiering Service ensures that recent data remains instantly queryable while historical records are archived economically.
In this blog post we will take a deep dive and explore how Fluss’s Tiering Service orchestrates data movement, preserves consistency, and empowers scalable, high-performance analytics at optimized costs.